RAG: A Bird’s Eye View
The rapid pace in which the Generative AI arena is evolving is fascinating and overwhelming. This domain is witnessing tremendous impact on the way organizations accomplish computing with the whirlwind innovations taking place in the arena. A relatively new term that is burgeoning in the Gen AI business world is Retrieval Augmented Generation.
RAG is a Natural Language Processing (NLP) technique that combines the power of Information Retrieval and Generative-capability AI models. In a simple way RAG can be defined as a superset of traditional Generative AI LLM models. This blog attempts to decipher how RAG works, its business implications, how it differs from fine tuning of LLMs, and the implementation considerations your organization should focus on while embracing RAG models.
The following two analogies help you to familiarize and reinforce the concept of Retrieval Augmented Generation with ease.
Decoding the LLM vs. RAG with Examination
The first analogy is of Open Textbook Exams and Closed Textbook Exams. In Closed Textbook Exams students are expected to retrieve information from their memory and write the exams whereas in Open Textbook Exams the student is free to refer textbooks or reference books and need not rely on the concepts memorized in the brain, isn’t it?
Similarly, a Large Language Model (LLM) generates answers to your queries by relying on past trained data (like Closed Textbook Exams). It lacks the flexibility to generate answers by referring to any new developments that have happened in the field post the date the model was trained.
On the contrary, a RAG generates answers to your prompts by referring to the authoritative data available in the public domain on the fly by scanning recent data/information and thus making the answers more relevant, informative, and including the latest advancements that happened around the topic.
RAG Unplugged: LLM and the Search Engine Tango
The second analogy can be of a ‘Search Engine plus LLM’ combo. As mentioned, an LLM generates text based on the data that it is trained on. It has limited power to answer questions on any recent developments that have occurred post the date on which it was trained.
But if an LLM can refine its answers by retrieving information from a Search Engine, Obviously it can generate non-stale and hallucination-free answers. So, In a nutshell, RAG exhibits the power of a Specialized Search Engine working in tandem with LLM.
Exploring RAG in Detail: A Deep Dive
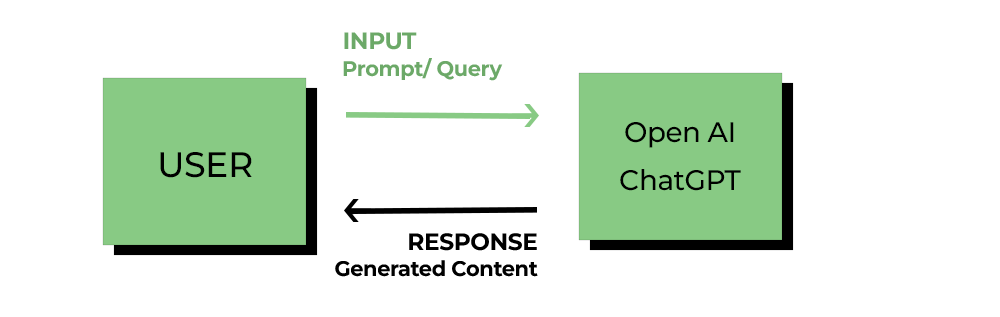
Before delving into the working of RAG models. Let us differentiate between Traditional LLM and RAG. A Traditional LLM responds to a user by simply ingesting the query. The generated response relies on the pre-trained data it holds. A RAG takes a deviation from this approach and integrates LLM with a searchable knowledge base. This approach helps the model to query the input prompt in an external dataset, thus enabling it to generate contextual and factually precise information based on the new learning.
Concisely, A RAG works with a synergy between LLM like GPT-4 and powerful Information Retrieval Systems to produce up-to-date, hallucination-free information, and provide access to private and proprietary data-based content that is factual.
The following Block diagrams help you understand the salient differences between Traditional LLM and RAG.
Block diagram Traditional LLM:
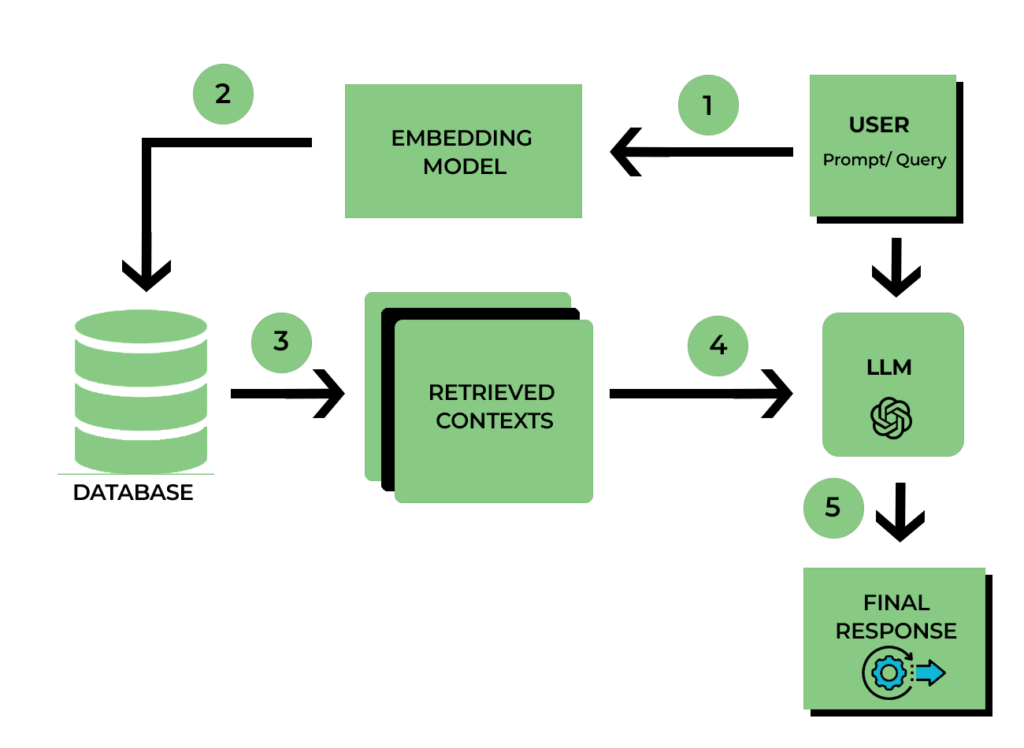
Block Diagram: RAG
Impact of RAG on Natural Language Processing (NLP)
RAG has a profound impact on natural language processing tasks such as sentiment analysis, question answering, and chatbots as it enables such tasks to return accurate and context driven responses.
RAG produces impactful abstractive and coherent summaries for lengthy research papers and news articles whereas traditional extractive summarization techniques fail to do so.
RAG plays a vital role in producing domain specific content for various domains like medical, legal, banking, finance, automotive, manufacturing etc.
Leveraging data augmentation of external datasets offered by RAG can enrich low-resource languages and mitigate bias in automotive content generation systems, producing ethically standardized/compliant content.
How RAG Works
The THREE underlying components of a RAG system are:
- Retrieval Component
- Augmentation Component
- Generation Component
Retrieval Component’s objective is to fetch relevant information from external data sources such as knowledge base or database by utilizing the user prompt/query. This component plays a critical role in obtaining factually and contextually correct content. Internally a Retrieval Component relies on Specialized Algorithms or APIs to accomplish this task.
Augmentation Component is the next step of the RAG process. It aims to enhance the retrieved data to produce contextually relevant responses. The Augmentation Component employs techniques like entity recognition, sentiment analysis, or simple text manipulation to enhance the quality of the query.
The Generation Component of RAG process produces original content based on the Retrieved and Augmented information. It relies on pre-trained models to accomplish this task.
How RAG Helps Surpass LLM’s Constraints
Basically, Generative AI models like LLM have three main limitations. Firstly, they may produce outdated or stale content as they might be not aware of recent developments in a domain we are working on. Though we can train the model using present data it involves more computing power and time.

Secondly, LLMs may cook up or fabricate answers if they really don’t know the correct answer. In the Generative AI arena, such fabricated content is called hallucination.
Finally, the pre-trained models do not have access to organizational proprietary or private data. Though this works as an advantage as your business data is not exposed to the outside world it also hinders the LLM model from generating organization specific content. The way out is to use a locked-down version of LLM to work on your private data but again it involves time, cost, and computing power.
In this context RAGs have the capability to retrieve indexed data from authoritative sources and fine-tune the query prompt in the form of augmented queries to LLMs to[19] produce up to date, hallucination-free, and domain specific content. This process of gaining knowledge from authoritative external datasets is known as grounding.
Fine Tuning LLMs vs. RAG: Which one to Choose?
Those of you already working with LLMs and have knowledge of prompt engineering might be wondering that while Fine tuning LLMs will help you to provide new knowledge to them and what is the necessity of RAG models?
In this section we have tried to answer how Fine Tuning LLMs differ from RAG models. Also, we have identified when you must go for RAG or Fine Tuning.
Fine-tuning LLMs means employing a pre-trained language model and adjusting its parameters to be specialized in a particular task or area. This technique is suitable for continuing the training process on a smaller, task-specific dataset.
RAG works by combining an information retrieval system and an LLM model. First, a retrieval system scans a huge dataset to fetch relevant context or facts. The obtained information is provided to the LLM model to generate a context-rich output. This model is apt for tasks where contextual or factual information is crucial.
Choosing between RAG vs. Fine Tuning
| Scenario | RAG Model (Preferred) | Fine Tuning LLM (Preferred) |
| Extract Information from External Data Source (External Knowledge Required) | Yes | No |
| Changing Model Behavior Required | No | Yes |
| Eliminate Hallucinations | Yes | No |
| Training Data Readily Available | No | Yes |
| Dealing with Dynamic Data | Yes | No |
| Interpretation of Data Needed | Yes | No |
Business Impact of RAG
RAG systems have evolved beyond the capabilities of providing conversational agility. They have a critical role in transforming business activities. Here’s why business leaders should pay attention:
Business Transformation: RAG systems exhibit capabilities to automate complex tasks, extract nuanced insights from data, and revolutionize decision-making. Thus, by integrating RAG into business processes, enterprises can achieve visible outcomes.
Hybrid Cloud Mastery: Organizations with expertise and dexterity in managing hybrid cloud are well-positioned to implement generative AI, including RAG. CTOs of organizations with mastery over hybrid cloud management can build systems that can leverage Open-source LLMs and at the same time keep the insights driven from proprietary data secure.
RAG is not only about solving complex tasks, it offers a paradigm shift in the way organizations work by putting AI technology on the forefront of business strategy and innovations.
How RAG Enhances Decision-Making, Customer Interactions, and Data Utilization
Redefining Customer Experience
In the customer service industry, RAG equips organizations with personalization and efficiency in retrieving customer data by seamlessly addressing complex queries with unparalleled accuracy.
Empower with Accurate Data-Driven Decisions
It enables organizations to make critical decisions based on insights extracted from vast data repositories. No matter whether we are contemplating to optimize supply chains, predict market trends, or unearth potential growth opportunities RAG helps decision-makers with actionable insights.
Be Creative with Content Creation
RAG isn’t only about building conversations; it extends to content creation. It helps organizations to create AI-generated reports, articles, or marketing materials aligned to the brand voice and resonate with the audience.
Tap Organizational Data
RAG helps organizations to rely on their organization’s knowledge base instead of merely depending on open source LLMs.
Implementation Considerations
Organizations planning to implement RAG process should focus on the following three aspects:
- Infrastructure Considerations
- Training data and Fine-tuning the models
- Integration with the existing systems
Further infrastructure requirements can be classified as:
Scalable Compute Resources: RAG in general and LLM in particular require huge computing power. So organizations should invest in scalable cloud computing resources or on-premise resources to reap its benefits.
GPU Acceleration: Training and inference with RAG models require Graphic Processing Units. GPUs accelerate the process of model training, thus investing in these components is vital.
Robust Storage Solutions: Storage solutions are vital to maintaining large-scale training data, pre-trained models, and retrieval indices. So investing in distributed file systems or object storage services to manage the storage needs is vital.
API Gateway and Load Balancers: API gateway and load balancers help to communicate between RAG services and external applications. These components manage traffic, distribute requests, and maintain system reliability.
Training data and Fine-tuning the models is the next implementation consideration
Curated Training Data: RAG’s success depends on having training data of the highest quality. Compile a varied dataset with goal generation, retrieval passages, and conversational context. To improve the performance of the model, annotate the data with appropriate details.
Fine-Tuning Strategies: It is imperative to fine-tune pre-trained LLMs using data particular to the domain. To customize the model for their needs, organizations can incorporate domain-specific corpora or internal data. Iterative fine-tuning raises the accuracy of the model.
Retrieval Corpus Creation: Create a retrieval corpus with pertinent papers, guides, or articles. These act as RAG’s retrieval basis. Elasticsearch and Solr are two efficient tools we can use to index the corpus.
The next implementation consideration is Integrating the RAG with the existing system. Here are the key points to be considered:
API Design and Endpoints: Define clear API endpoints for RAG services. These endpoints allow hassle-free integration between existing applications, chatbots, or content generation pipelines.
Middleware and Orchestration: Use middleware for message queuing and orchestration. It ensures smooth communication between RAG components and other services.
Security and Authentication: Implement robust security measures. Secure API endpoints with authentication tokens, rate limiting, and access controls. Protect sensitive data during retrieval and generation.
Monitoring and Logging: Set up monitoring tools to track RAG performance, response times, and resource utilization. Exhaustive logs help diagnose issues and optimize system behavior.
User Feedback Loop: Establish a feedback loop to improve RAG continuously. Gather user feedback, track model performance, and fine-tune based on real-world interactions.
Conclusion
Retrieval-Augmented Generation (RAG) emerges as a pioneer in Natural Language Processing (NLP), surpassing traditional Large Language Models (LLMs). While LLMs excel at generating text, they struggle with outdated information and factual inaccuracies. RAG bridges this gap by integrating LLMs with external knowledge bases, enabling them to access and leverage real-time data. RAG offers a multitude of benefits that revolutionize NLP tasks. Gone are the days of outdated information and fabricated responses.RAG ensures up-to-date and contextually accurate information, tailored to specific domains by leveraging even your organization’s private data. This empowers tasks like sentiment analysis and chatbots to deliver valuable insights. Furthermore, RAG facilitates content creation and informative summaries, while unlocking the true potential of your data for improved decision-making and personalized customer experiences.

The Future Ahead: RAG technology represents a significant leap forward in NLP, paving the way for more informative, accurate, and contextually aware interactions between humans and machines. By relying on the power of RAG, organizations can explore new possibilities for business transformation and innovation.

