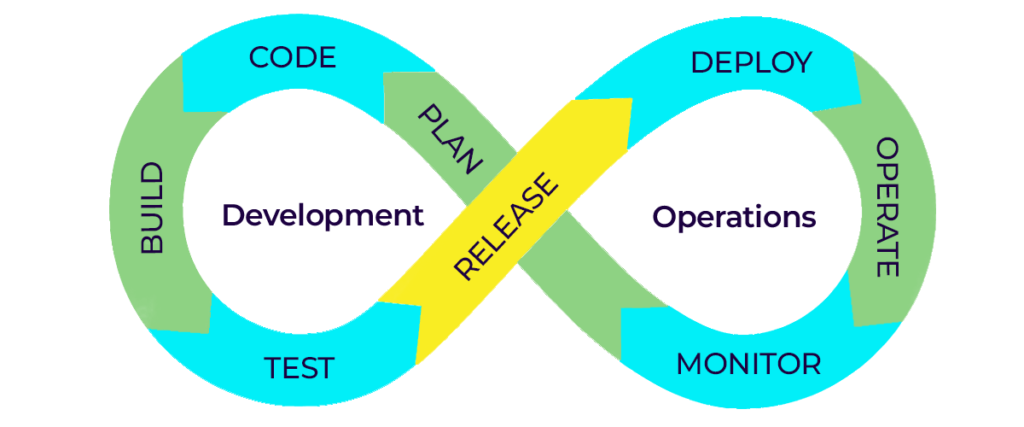
DevOps (Development & Operations) and MLOps (Machine Learning Operations) conceptually have a close resemblance you can term them as ‘Twins’!
DevOps brings together two teams Development and Operations and on the other hand MLOps ropes in Data Science, DevOps, and Machine Learning teams.
The term DevOps was introduced by Patrick Debois in the year 2009. It gained momentum when the Software Development and the Operations teams struggled to work in sync, Practitioners in the IT domain felt the need to get rid of ‘Silos’ and bring in coordination between the IT Development and Operations teams.
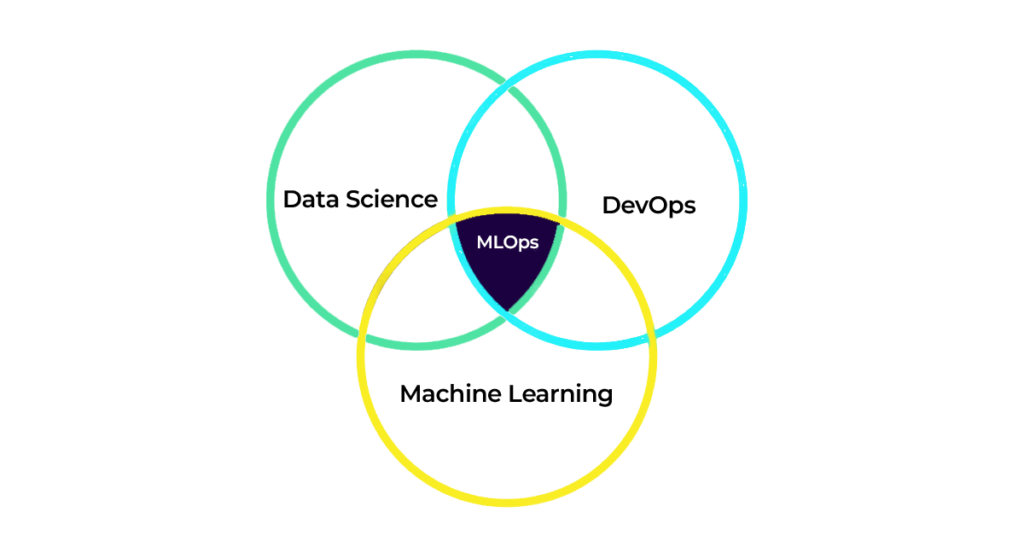
The extension of the idea of DevOps to bring in comprehensive coordination and collaboration between Data Engineering, DevOps, and Machine Learning teams is termed MLOps.
In a nutshell, MLOps is a blend of Machine Learning (ML), Data Science, and DevOps disciplines by ensuring they do not function as silos. The term MLOps was first coined in the year 2015.
MLOps and DevOps go hand in hand except that ML systems are ‘experimental in nature’ and possess complex to build, deploy, and operate components.
This blog deciphers MLOps, MLOps as a Service, steps of MLOps implementation, best practices to be followed during MLOps implementation, choosing between building vs. buying vs. hybrid MLOps solutions and finally interesting MLOps case studies that organizations should focus on their MLOps adoption journey.
MLOps vs. MLOps as a Service: Key Differences
You can define MLOps as a pool of practices enabling the creation of assembly lines for building and running Machine Learning models. It comprises tasks such as model development, training, and deployment.
The primary objectives of MLOps pipelines are to automate tasks of model deployments, establish seamless cooperation and collaboration between Data Scientists, Software Developers, and Operational Staff, and help organizations continuously improve the accuracy and performance of models.
On the contrary, MLOps as a Service is an extension of the core MLOps principles. It provides additional features like Managed Services so that you can outsource tasks like model deployment, monitoring, and maintenance. It offers a comprehensive and collaborative approach to end-to-end lifecycle management of Machine Learning models. On top of that, it enhances efficiency through pre-built pipelines, tools, and integrations. It can scale automatically as the ML adoption grows.
Dive Deep into MLOps as a Service
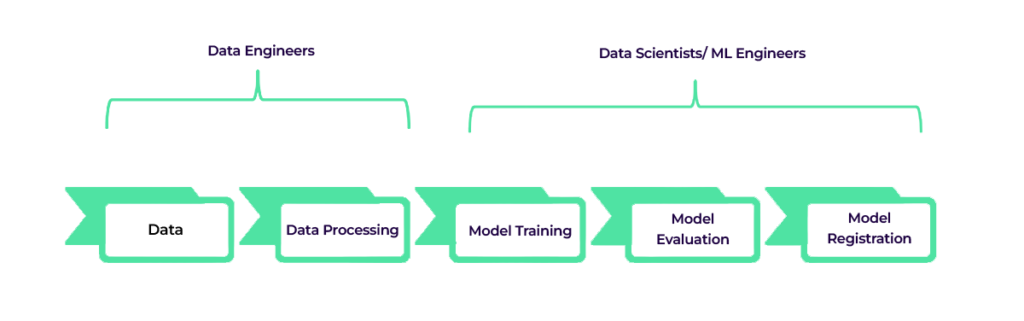
Data Engineering/ Experimentation Stage Block Diagram
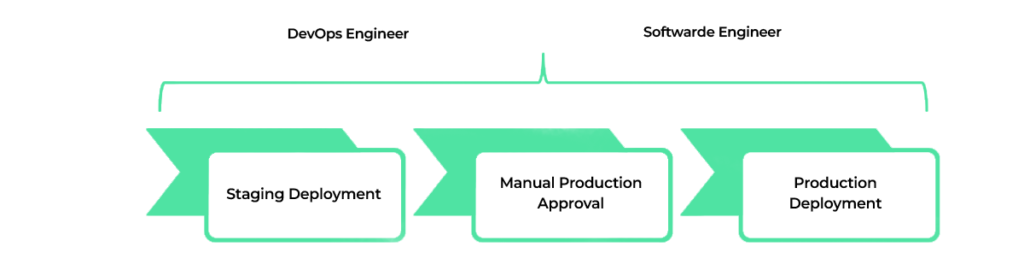
DevOps Engineering / Production Stage Block Diagram
A Typical MLOps Workflow
A typical MLOps workflow integrates the development, deployment, and monitoring of machine learning models. Here’s a breakdown of the key players and the components involved in implementing MLOps workflow:
The Players Who Make MLOps Workflow a Reality:
- Data Engineers: They focus on Data Collection and Preparation activities by collecting relevant data for model training. Further, they clean, preprocess, and engineer features for machine learning models.
- Data Scientist/ML Engineer: They focus on developing, training, and evaluating machine learning models.
- Lead Data Scientist: Supervises the data science team by providing senior-level guidance.
- DevOps Engineer: Acts as a bridge between development and operations teams. Ensures automation of ML model deployment.
- Software Engineer: Focus on developing features and integrating the ML model with the production application.
The MLOps Process Decoded (Step-by-Step Process):
Data Processing: In this step, Data Engineers gather raw data from various sources. This data is then cleaned, transformed, and prepared to suit the next step- Model training.
Model Training: In this step, the Data Scientists and ML engineers develop, train, and evaluate different machine learning models.
Model Selection & Registration: The evaluation and registration of the model tests the performance of the models and registers the models that are selected for deployment in a model registry.
Model Deployment: The selected models are deployed to a staging environment and the lead data scientist must approve them to be deployed in the production environment.
Monitoring & Feedback: The production environment monitors the model’s performance continuously. Metrics such as accuracy, precision, and recall are used to evaluate the performance. If model performance degrades it is redeployed by following retraining.
Governance and Compliance: In the production environment the deployed models are monitored to ensure compliance with regulations and ethical guidelines. Moreover, this step ensures version control and model governance.
IMPORTANT:
- Code/Configuration Changes: The code/configuration changes are meticulously monitored. This helps to trigger retraining and redeployment of the model and thus the model remains up-to-date and performs well for newly ingested data.
- Manual Approval: In addition to automated approval stages manual approval stages often help to ensure the quality and safety of the models before they are deployed to production.
MLOps as a Service (MLOPsaaS) Features
The primary objective of leveraging MLOps as a Service is to ease your workforce from building MLOps workflows from scratch and provide them the scope to focus on their key performance areas and be productive without spending time and resources on the mundane tasks of managing MLOps pipelines.
MLOps as a Service advocate Managed Services and here are its salient implementation features:
- Managed Infrastructure and Tools: MLOpsaaS offers pre-configured infrastructure and tools to build MLOps workflows. Your organization can leverage pre-built platforms or services without worrying about building workflows from scratch.
- Hassle-free Automated Pipelines: Your entire end-to-end ML lifecycle is streamlined by MLOpsaaS. Such automated pipelines handle data processing, model training, deployment, and monitoring seamlessly offloading your workforce to focus on other productive activities.
- Embracing Scalability and Flexibility: MLOpsaaS offers the power to scale seamlessly based on dynamically changing demands. It is flexible to varying workloads and data volumes. So, your workforce need not be overwhelmed by the rapid increase in the volume of the deployed ML models.
- Fosters Strong Collaboration and Integration: Adopting MLOpsaaS facilitates strong collaboration between all the stakeholders involved in the implementation of MLOps workflow like data scientists, ML engineers, and DevOps teams. Importantly it integrates with existing CI/CD pipelines and tools.
- Streamline Operations with Managed Monitoring and Governance: By choosing MLOpsaaS you can leverage built-in monitoring and alerting features. It ensures compliance, security, and efficient resource utilization.
Why MLOps as a Service?
Deploying ML models with the core MLOps principles comes with various challenges.
Complexity Challenge: The first challenge is dealing with the complexity. Unlike handling typical DevOps pipelines, deploying MLOps models is not about writing software code. It comprises intricate steps of data processing, model training, evaluation, deployment, and continuous monitoring. This demands meticulous consideration and coordination between all the teams involved.
For instance, say your organization is building a recommendation system for an e-commerce platform. It can throw down a dozen complexity issues such as cleaning and transforming raw user interaction data into a format suitable for the proposed model.
Model training will be complex as you must choose the right algorithm, tune hyperparameters, and train the model using a large dataset.
During Deployment, transitioning from the experimental setup to the production environment is a challenging task as ensuring the trained model works seamlessly by using the existing infrastructure.
Finally, monitoring such model’s performance, detecting drifts, and retraining them are all complex.
Scalability Challenge: As the number of ML models deployed by your organization grows, and complexity spectrum also varies. The scalability issue becomes challenging. Each model has its own requirements, dependencies, and versioning. So, scaling up to meet the demands becomes vital.
For example, consider a healthcare organization employing ML models for patient risk prediction, disease diagnosis, and treatment recommendations. As the number of services grows, they must manage models for various medical conditions, patient demographics, and treatment protocols. Ensuring consistent deployment, monitoring, and updates for all the models demands robust scalability.
Cost Effectiveness: Investing in-house ML infrastructure by building them from scratch can be expensive. It includes vivid costs such as hardware procurement costs, cost of cloud resources, licensing fees for specialized tools, and personnel salaries for the staff building and deploying these ML models.
Say, as a financial institution you are keen on deploying credit risk assessment ML models. So, you must invest in powerful GPUs or cloud instances for model training. Additionally, your organization needs data engineers, data scientists, and DevOps specialists to manage the infrastructure. Such costs keep growing exponentially as you start deploying more and more models.
To conclude, relying on MLOps as a Service helps you to offload many of these tasks by outsourcing to an organization with expertise in providing automated pipelines, version control, and efficient infrastructure management. Organizations that embrace MLOps practices can navigate the complexities, scale effectively, and optimize costs while deploying and maintaining ML models.
Benefits of MLOps as a Service
• Efficiency: Outsourcing your MLOps workloads streamlines deployment, monitoring, and maintenance.
• Cost-Effectiveness: Embracing MLOps as a service offers the benefit of Pay-as-you-go models and reduces infrastructure costs.
• Empowers to Focus on Core Business: Using MLOps as a Service empowers your team to focus on your core deliverables, and innovation and not worry about mundane operational tasks.
Impact of ML Models on ROI
No doubt the motive of embracing any new technologies or disruptions is to keep pace with the changing needs of the world but most importantly the ROI it delivers is key for any business. MLOps is no exception.
MLOps enables organizations to handle two major challenges:
- Faster and Accurate Decision Making
- Reducing the Operation Costs
Yes, adopting MLOps workflows and models enhances the decision-making capabilities of an organization through data-driven insights.
Further, efficient model deployment and monitoring minimize operational overhead. The automation reduces manual effort, saving time and resources and thus bringing down operational costs dramatically.
How to Implement MLOps as a Service
Google has come up with comprehensive research about the ways MLOps can be implemented. THREE popular approaches identified are named as follows:
- MLOps level 0 or (Manual Implementation Process)
- MLOps level 1 or (ML Pipeline Automation Process)
- MLOps level 2 (CI/CD Pipeline Automation Process)
Let us delve into the details of these three approaches:
MLOps Level 0
This approach is best suited for organizations that are just beginning their journey to the ML arena. This approach advocates an entirely manual ML workflow and the data-scientist-driven process as your models rarely change or are rarely re-trained.
Salient Traits of MLOps Level 0 Approach
Completely manual, script-driven, and interactive process: The entire process is manual, no matter whether it is data analysis, data preparation, model training, or validation. The entire process is driven in a step-by-step way through complete human intervention.
ML and Operations Work in Disjoint Mode: In this process, the data scientist team and deployment engineer teams work in a disconnected style. The data scientists, hand over a trained model as a product for the engineering team to deploy using API infrastructure.
Infrequent Releases: In the MLOps Level 0 approach the fundamental assumption is that your models won’t change frequently, and the data science team manages a few models. As a result, frequent model retraining needs do not arise, thus a new model version is deployed only a couple of times per year.
No Continuous Integration (CI) or Continuous Deployment (CD): As few implementation changes are assumed there is no need for CI. Also, as the number of model versions is less CD pipeline is not a necessity.
Non-existence of Active Performance Monitoring: This process will not track or log model predictions and actions.
Challenges
In the real world, models often break when they’re deployed. Models fail to fit to changes in the dynamically updating environment or to changes happening in the data front.
To overcome these challenges encountered in the manual process, it is good to use MLOps practices for CI/CD and CT. MLOps Level 1 advocates the same.
MLOps Level 1
The objective of MLOps Level 1 is to accomplish continuous training (CT) of the model through automation of the ML pipeline. This enables you to achieve continuous delivery of model prediction service. This solution aptly suits scenarios where the environment constantly changes and you must proactively handle shifts in customer behavior, prices, and other parameters.
Salient Traits of MLOps Level 1 Approach
Instant Experiments: In this approach, the Machine Learning experimentation steps go through orchestration and automation.
Continuous Training of Models in the Production Stage: Live pipeline triggers are used to train the models automatically in production, through new data and live pipeline triggers.
Striking Symmetry between Experiment and Production Environments: The same MLOps pipeline is used in both the experiment environment and the production environment, which is the striking feature of MLOps practice for unifying DevOps.
Modularization of Code: For effective construction of ML pipelines, components should be reusable, composable, and shareable across ML pipelines (i.e. usage of containerization concept).
Changeover to Pipeline Deployment from Model Deployment: While the level 0 approach deploys a trained model as a prediction service to production, level 1 deploys the entire training pipeline, which automatically and periodically executes to assist the trained model as the prediction service.
Challenges
The level 1 approach is suitable when you must deploy new models based on new data, and not based on new ML ideas. But when the requirement is to deploy new models based on new ML ideas and rapidly deploy new implementations of the ML components then transition to MLOps Level 2 approach is advocated.
MLOps Level 2
Implementing an automated CI/CD system enables data scientists to explore new ML ideas that revolve around feature engineering, model architecture, and hyperparameters. Such automated CI/CD system assists in rapid and steadfast updating of production pipelines.
Tech-driven companies that require frequent retraining of their models on daily basis and update them in minutes and redeploy to thousands of servers parallelly should go for MLOps Level 2 implementation.
Salient Traits of MLOps Level 2 Approach
Sync between development and experimentation: Say your organization iteratively experiments with new ML algorithms and new modeling with orchestration. Further, the output of the experimentation stage is the source code of the ML pipeline stages, which are then pushed to a source repository. Such a scenario demands for level 2 approach.
Implementing pipeline continuous integration: Assume your team builds source code and runs various tests in the first stage. The outputs of this stage are pipeline components that must be deployed in a later stage. This scenario aptly demands level 2 implementation.
Realizing pipeline continuous delivery: Consider a scenario where your team deploys the artifacts produced by the CI stage to the target environment. Further, the output of this stage is a deployed pipeline with the new implementation of the model. This is a typical trait of a Level 2 MLOps.
Adopting automated triggering: Assume your pipeline is automatically executed in production based on a schedule or in response to a trigger. Moreover, the output of this stage is a newly trained model that is pushed to the model registry. Here too Level 2 MLOps implementation is a natural fit.
Model continuous delivery: Say your team serves the trained model as a prediction service for the predictions and the output of this stage is a deployed model prediction service.
IMPORTANT:
It is important to note that despite the automation spree in level 2, the data analysis step requires manual processing by data scientists before the pipeline starts a new iteration of the experiment. The model analysis step is also a manual process.
Best Practices for MLOps Implementation
We have categorized the best practices to be adhered to during MLOps implementation into SIX ML components: Team, Data, Objective, Model, Code, and Deployment.
| ML Component | Best Practices |
| Team | Utilize the services of a Collaborative Development Platform |
| Say ‘NO’ to Shared Backlog | |
| Teamwork Triumphs: Communication, Alignment, and Collaboration are key to success | |
| Data | Filter out the chaff from all external data sources by comprehensive check. |
| Monitor and identify changes in data sources. | |
| Embrace reusable scripts for data cleaning and merging needs | |
| Modify existing features to be human-readable | |
| Ensure the datasets are available on shared infrastructure | |
| Objective (Metrics & KPIs) | Select a simple metric for your first objective |
| Implement Fairness and Privacy | |
| Model | Ensure the first model is simple and select the right infrastructure |
| Use Parallel Training Experiments | |
| Code | Run Automated Regression Tests |
| Use Static Analysis to Check Code Quality | |
| Deployment | Plan to launch and iterate. |
| Continuously monitor the Behaviour of Deployed Models |
Interesting Facts and Case Studies
Now it is time to investigate some interesting case studies where popular and pioneering organizations have adopted MLOps workflow to empower their stakeholders and streamline operations. Here we have chosen the success stories of Netflix, Google, and Uber.
1. Netflix’s Chaos Monkey: Building Robust & Resilient ML Models
Background: Netflix is a global streaming giant and a household name in the entertainment industry. This organization heavily relies on machine learning algorithms to produce personalized content recommendations for its users.
Challenge: The challenge Netflix accepted is to build robust ML models that perform reliably under unexpected conditions like server failures, network glitches, or sudden spikes in user traffic.
Solution: Netflix developed a chaos engineering tool called Chaos Monkey. This tool deliberately introduces disruptions into the production environment to test system resilience. Chaos Monkey can randomly terminate instances and simulate real-world failures.
Outcome: By putting Chaos Monkey into action, it helps to detect vulnerabilities in Netflix’s ML infrastructure thus empowering ML engineers to build more reliable and resilient ML services.
2. Google’s AutoML: Democratizing MLOps by Catering to Non-Techies
Background: Google needs no introduction, and their ‘Google AutoML’ is a product envisioned to democratize machine learning by making it accessible to non-computing users.
Challenge: Working with traditional ML models demands specialized knowledge and skills from data engineering, DevOps, and Machine Learning disciplines. Thus, it limits the adoption rate amongst common users.
Solution: The AutoML is built to simplify the model creation process. Moreover, it automates tasks like feature engineering, hyperparameter tuning, and model selection.
Outcome: AutoML has helped vivid businesses across various domains to realize custom ML models without the need for deep domain expertise. Now retail, healthcare, banking, automobile, hospitality, or any business can leverage ML effectively.
3. Uber’s Michelangelo: Redefining Ride-sharing Services
Background: Uber, a renowned player in the ride-sharing domain, handles massive amounts of data for real-time decision-making.
Challenge: Deploying and managing ML models at scale across a diverse set of use cases.
Solution: Uber developed Michelangelo, an end-to-end ML platform. It provides tools for feature engineering, model training, deployment, and monitoring.
Outcome: Michelangelo has enabled Uber to optimize pricing, personalize recommendations, and enhance safety using ML. It handles millions of predictions per second.
Conclusion
Your organization must identify the trade-offs between time and effort, human resources, time to profit, and opportunity cost before choosing between buying, building, or opting for hybrid MLOps infrastructure.
Your organization can go with one of two MLOps solutions:
- End-to-end MLOps Solutions
- Custom-built MLOps Solutions
The End-to-end MLOps solutions are fully managed services that facilitate developers and data scientists with the ability to build, train, and deploy ML models quickly.
Whereas your organization can build your own MLOps solutions with your favorite tools, by utilizing multiple microservices.
This approach offers a big advantage as it avoids a single point of failure (SPOF) making your pipeline robust. Furthermore, it is easier to audit, debug, and more customize your pipeline with customized solutions. In case a microservice provider is having problems, you have the flexibility to plug in a new one.


